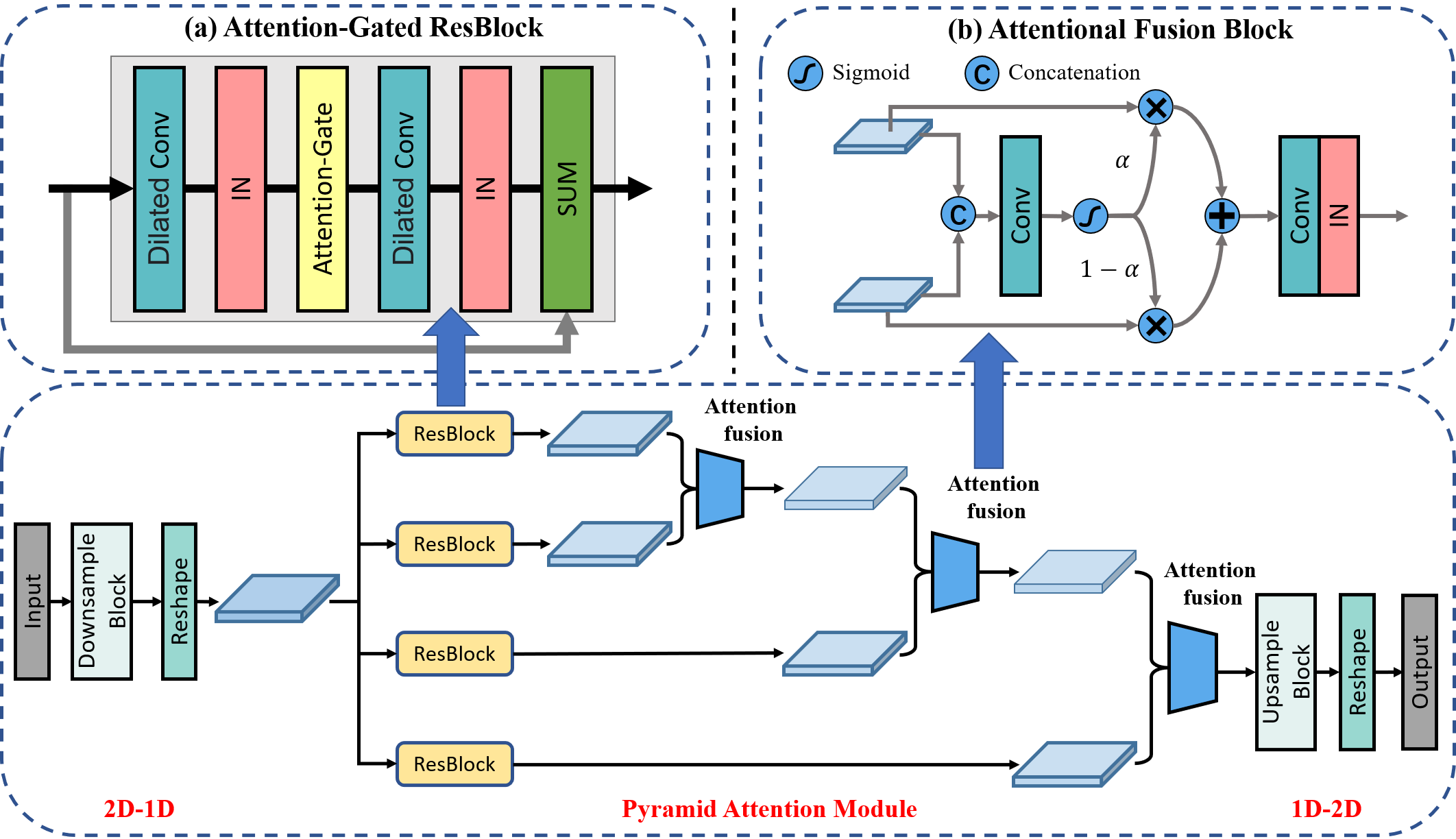
PACycleGAN-VC
Non-parallel voice conversion (VC) is a voice mapping technology that uses non-parallel corpus to convert source speeches into target speeches while maintaining semantic information unchanged. Recently, Cycle-consistent adversarial network-based VC with Filling in Frames (MaskCycleGAN-VC) [1] is proposed and generally accepted as current benchmark method. While it solves the problem of time-frequency structures consistency, the performance of voice conversion is not satisfactory enough, especially in inter-gender VC. There is still a large gap between target and converted voice in terms of naturalness and similarity. In addition, the performance of MaskCycleGAN-VC seriously deteriorates because of a limited amount of training data. In order to solve above problems, we propose Pyramid Attention CycleGAN (PACycleGAN) for voice conversion which integrates pyramid structure and attention mechanism. We use Differentiable Augmentation, a method that improves the data efficiency of GANs and makes training more stable by imposing different types of differentiable augmentations on both real and fake speech samples. We evaluate the performance of PACycleGAN on inter-gender and intra-gender non-parallel VC. Subjective and objective evaluations of naturalness and speaker similarity show that PACycleGAN-VC outperforms MaskCycleGAN-VC for every VC pair.
Conversion samples
Recommended browsers: Safari, Chrome, Firefox, and Opera.
Experimental conditions
- We evaluated our method on the Spoke (i.e., non-parallel VC) task of the Voice Conversion Challenge 2018 (VCC 2018) [2].
- For each speaker, 81 sentences (approximately 5 min in length, which is relatively short for VC) were used for training.
- The training set contains no overlapping utterances between the source and target speakers; therefore, we need to learn a converter in a fully non-parallel setting.
- We used MelGAN [3] as a vocoder.
Compared models
- Mask: MaskCycleGAN-VC [1]
- PA: PACycleGAN-VC
Results
- Female (VCC2SF3) → Male (VCC2TM1)
- Male (VCC2SM3) → Female (VCC2TF1)
- Female (VCC2SF3) → Female (VCC2TF1)
- Male (VCC2SM3) → Male (VCC2TM1)
Female (VCC2SF3) → Male (VCC2TM1)
| Source | Target | Mask | PA | |
|---|---|---|---|---|
| Sample 1 | ||||
| Sample 2 | ||||
| Sample 3 |
Male (VCC2SM3) → Female (VCC2TF1)
| Source | Target | Mask | PA | |
|---|---|---|---|---|
| Sample 1 | ||||
| Sample 2 | ||||
| Sample 3 |
Female (VCC2SF3) → Female (VCC2TF1)
| Source | Target | Mask | PA | |
|---|---|---|---|---|
| Sample 1 | ||||
| Sample 2 | ||||
| Sample 3 |
Male (VCC2SM3) → Male (VCC2TM1)
| Source | Target | Mask | PA | |
|---|---|---|---|---|
| Sample 1 | ||||
| Sample 2 | ||||
| Sample 3 |